
Bridging the Gap Between Virtual Machines and Kubernetes with KubeVirt
This blog post will provide a brief introduction to the open source CNCF project KubeVirt. KubeVirt (alongside Kernel-based Virtual Machine (KVM)/libvirt/QEMU) is one of the foundational components included in OpenShift Virtualization. A more detailed relationship can be found on the Hyperconverged Cluster Operator for OpenShift Container Platform (OCP). While this blog post shall be focused on the upstream project KubeVirt, I have to provided full credit to OpenShift Virtualization along the lines, because most of my lessons learned are originated there.
If you are just interested in the demo, please head over to section KubeVirt with libvirt/QEMU/KVM in kind.
Why KubeVirt / OpenShift Virtualization?
KubeVirt / OpenShift Virtualization allows you to operate virtual machines (VMs) on Kubernetes / OpenShift. I have come across several different reasons why companies would want to look into this topic. Please let me elaborate on some reasons:
- Migrate VMs to microservices at your pace
- KubeVirt / OpenShift Virtualization can be an interim solution when you are migrating your workloads towards containers anyway and need to host them on your k8s based platform temporary. This is especially true when you are using the Migration Toolkit for Virtualization on OpenShift for the initial migration.
- Legacy applications need VMs
- Some applications might not be worth to modernize to container technology as their is no commercial benefit. Thus you will leave them as is in a VM until the end of the application lifecycle.
- Reduce technology spread (Hypervisor + K8s / OCP)
- Some companies are looking for a way to reduce the technology spread in their existing infrastructure.
- Replace hypervisor and save costs $$$
- The layer of a hypervisor is introducing additional costs on your infrastructure which can be avoided when using kubernetes / OpenShift on bare metal servers.
- Need virtualization technology for certain requirements
- Companies could be forced to use virtualization technology to comply with some of their requirements, especially in the realm of public and critical infrastructure.
Why OpenShift Virtualization instead of upstream KubeVirt?
From the above reasons you could think that OpenShift Virtualization might be fully interchangeable with KubeVirt. Nevertheless there are some key differences:
- OpenShift Virtualization is running on OpenShift thus uses Red Hat Enterprise Linux CoreOS (RHCOS) as the underlying operating system.
- RHCOS is the downstream version of Fedora CoreOS.
- Red Hat has a very long and successful history with
- Red Hat Enterprise Linux (RHEL) and
- Virtualization with the KVM/libvirt/QEMU stack in Red Hat Virtualization and Red Hat OpenStack Platform
- OpenShift has full commercial support from Red Hat. This includes multi-vendor support which can be relevant especially when you are facing issues on the storage side.
- OpenShift Virtualization can be easily setup and managed throughout the lifecycle via the Operator Lifecycle Manager on OpenShift.
How does KubeVirt work?
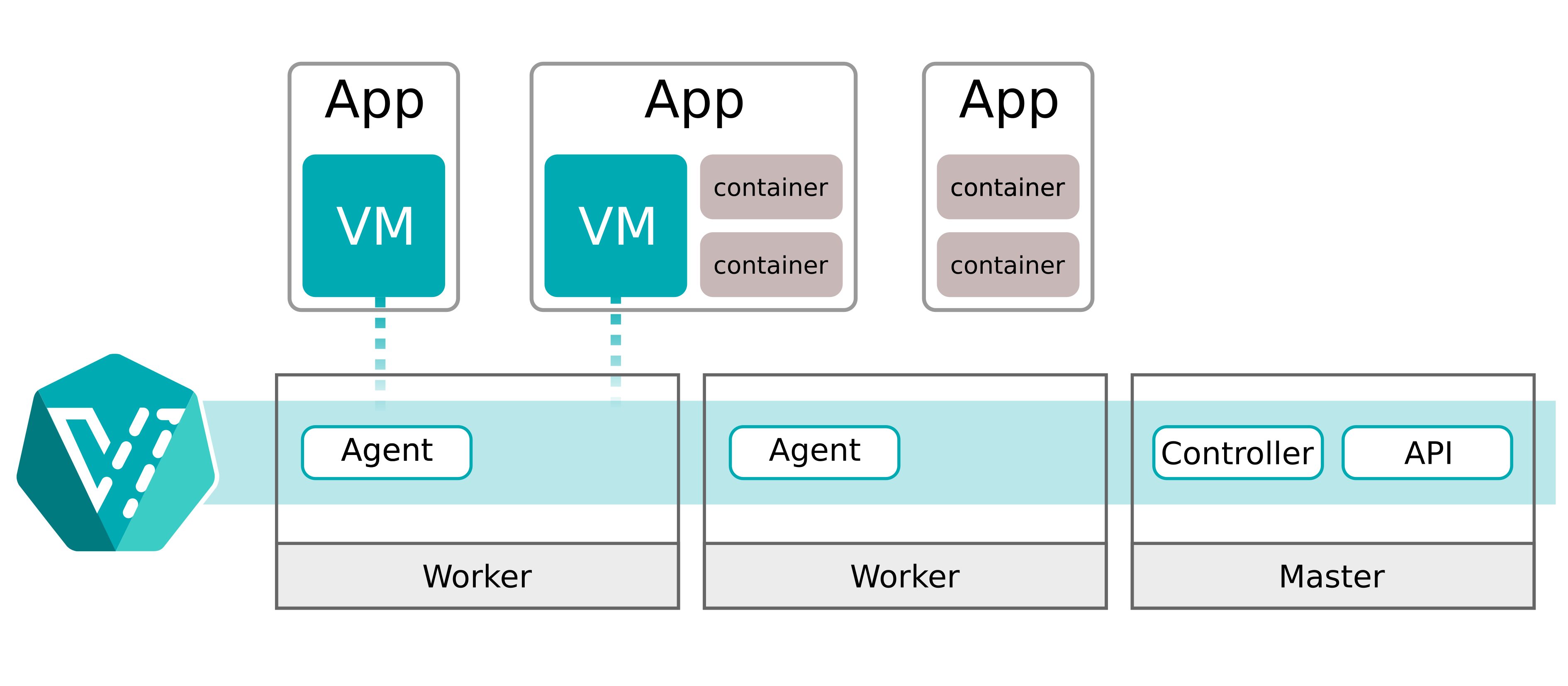
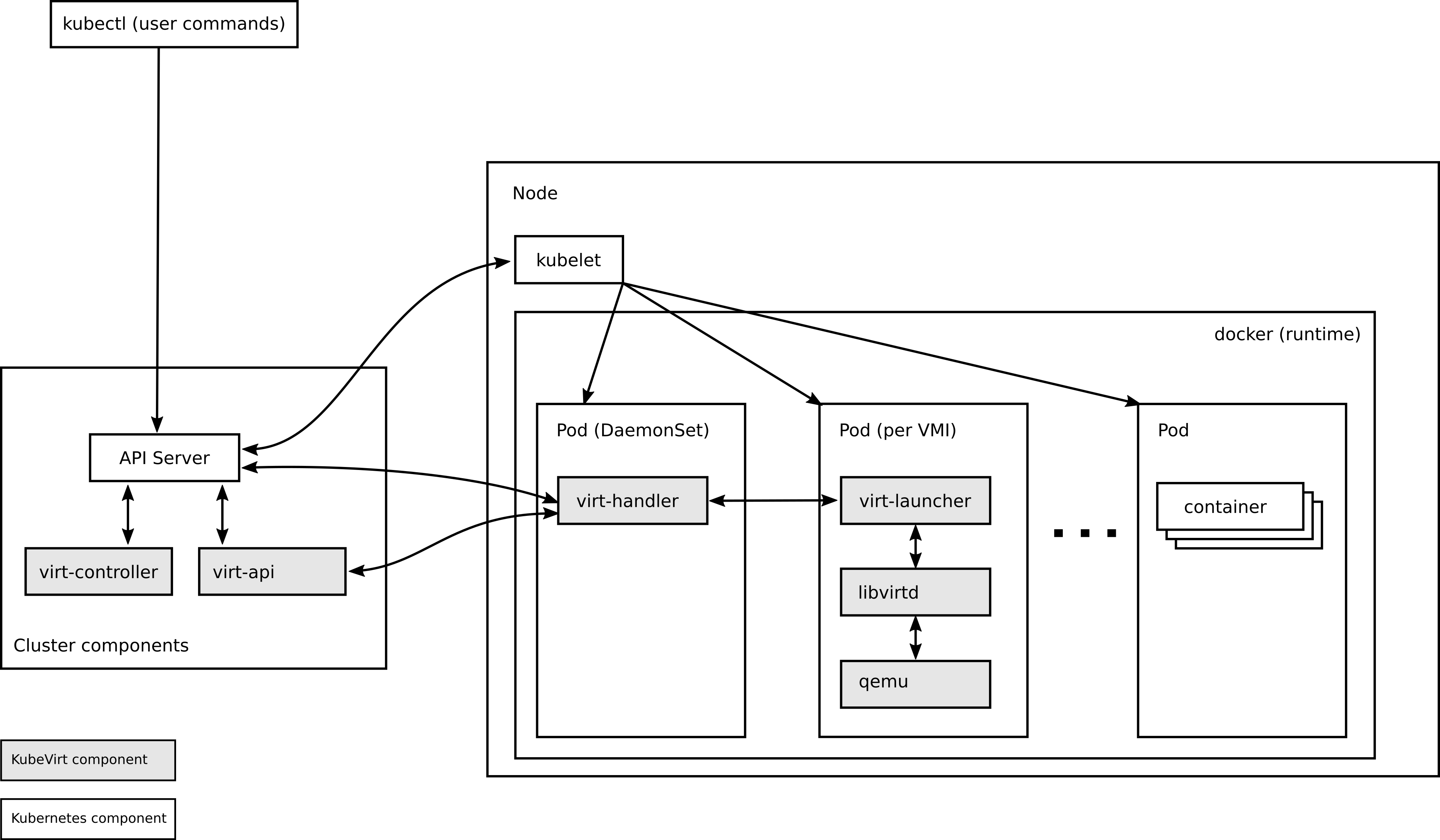
A detailed explanation about KubeVirt can be found on the official KubeVirt website. Simply put, KubeVirt will provide a Controller and API server on the control plane and some Agents on the worker nodes. You can interact with the custom resources via the kubernetes API server which will allow you to interact with the virtual machines. The virtual machines are created via the libvirt daemon which leverages QEMU and the KVM components on Linux.
KubeVirt with libvirt/QEMU/KVM in kind
Before we move ahead make sure to provision the setup on a linux machine, because there you will have access to the libvirt/QEMU/KVM stack. Other platform, e.g. MacOS, might use other hypervisor technology and you could run into issues. More specifically, you might run into kubevirt/issues/11917 on Apple hardware.
Setup kind and KubeVirt
To setup your machine please follow these instructions:
- Setup
kubectl - While I generally advocate for the rootless
Podman, it is easier to get started with theDockerdriver - Setup
kind - Install
virtctla binary from the KubeVirt project to manage the VMs- Via Github
1 2 3 4 5 6export VERSION=$(curl -s https://storage.googleapis.com/kubevirt-prow/release/kubevirt/kubevirt/stable.txt) ARCH=$(uname -s | tr A-Z a-z)-$(uname -m | sed 's/x86_64/amd64/') || windows-amd64.exe echo ${ARCH} curl -L -o virtctl https://github.com/kubevirt/kubevirt/releases/download/${VERSION}/virtctl-${VERSION}-${ARCH} chmod +x virtctl sudo install virtctl /usr/local/bin - Via
krew1kubectl krew install virt
- Via Github
- Install the libvirt/QEMU/KVM stack for your linux distribution. For Fedora you can find a guide here
Provision kind cluster with KubeVirt
First of all we create a cluster with one control-plane node and two worker nodes:
| |
Then we create a bash script which does the following:
- Create a
kindcluster with thekind-config.yamlconfig - Following the kubevirt instructions to install the kubevirt operator
- Following the kubevirt lab to provision and start an ephemeral container disk VM
- Following the kubevirt instructions on Containerized Data Importer (CDI) operator to provision a persistent VM
| |
Experimenting with the containerdisk VM
After executing the above bash script we should have the following nodes:
| |
We have applied the following VirtualMachine to the cluster:
| |
This is a VirtualMachine which uses a containerDisk. A containerDisk is a ephemeral VM disk from a container image registry. We have not claimed any persistent storage with this VirtualMachine. Consequently will a reboot of this VM also result in a loss of all data.
| |
Despite the fact, that the use of a containerDisk is not the main goal of KubeVirt, we can still use this VirtualMachine to understand the behaviour of KubeVirt components.
There should be a VirtualMachine in Running state:
| |
When a VirtualMachine is running, then there should also be a VirtualMachineInstance with the exact same name testvm:
| |
The VirtualMachine is actually running inside the virt-launcher-testvm-65f42 Pod:
| |
We can now check which processes are running inside this virt-launcher-testvm-65f42 Pod:
| |
Note: To get the full output of ps -ef it is easier to kubectl exec -it ... -- /bin/bash and then obtain the output with ps -ef | more.
Let us elaborate on the above ouput in more detail.
We can see that the container is started with PID 1 from /usr/bin/virt-launcher-monitor which creates another process via /usr/bin/virt-launcher. The virt-launcher created another process via the libvirt QEMU management daemon /usr/sbin/virtqemud.
What we can also clearly see is why the libvirt project exists as an abstraction layer. Starting the qemu-kvm with PID 89 with all of the parameters would be a very tough challenge without the libvirt layer in between.
If we want to look at the process tree more compactly, we can use pstree:
| |
We can also leverage the libvirt project so see and understand the running VM.
| |
In theory you could also manipulate the VM state with the virsh commands, but this is not the real intention of the KubeVirt project. Nevertheless, we will do that for the sake of our understanding. With virsh destroy <DOMAIN> we can forcefully stop a VM:
| |
The VirtualMachine will automatically be restarted because we have set the spec.runStrategy: Always with our startup script.
| |
We can also access the VirtualMachine with the virtctl console command. Let’s create a file inside the VM:
| |
Now let us migrate the VM to another node and observe the virtualmachineinstancemigrations:
| |
The migration is completed, which we can also observe on the Pods, as the virt-launcher-testvm-v5h4f on node kind-worker is gone and spawned another one on kind-worker2. The VirtualMachine is still running:
| |
As pointed out earlier, a restart of the VM will result in a loss of all data due to the containerDisk:
| |
Experimenting with a persistent VM
Now let us take a look at a VirtualMachine which is using a Read Write Once (RWO) persistent storage and a fedora 41 cloud image. This VirtualMachine is relying on the Containerized Data Importer (CDI) installed with the previous bash script. The CDI will import the cloud image into a DataVolume which is an abstraction on top of a Persistent Volume Claim (PVC).
| |
This VM has dedicated cpu resources in .spec.template.spec.domain.cpu which are actually the default values. Additionally we are installing httpd, operate it on port 8080 and write our custom index.html file via the cloud-init.
Let’s create the VM and expose a NodePort service:
| |
We can also reach it with curl:
| |
This VirtualMachine is now utilizing a persistent storage via DataVolume and PVC:
| |
Note: The PVC is RWO, which does not allow us to live migrate the VM between hosts. Thus we had explored the live migration with the containerDisk VM in the previous section.
We will test the persistency of the storage:
| |